Mixed-Frequency Data#
by Professor Throckmorton
for Time Series Econometrics
W&M ECON 408/PUBP 616
Slides
Summary#
In the Data in Python Notebook, we read one time series, Real GDP, from FRED.
This Jupyter Notebook will demonstrate how to use a
forloop to read and plot multiple time series in Python.These time series will have mixed frequencies, e.g., daily, monthly, quarterly, annual.
Reading data#
Let’s create a Data Frame with three columns, a
DATEindex,RGDP(Real GDP), andPCEPI(Personal Consumption Expenditures Price Index).Our goal is to plot the Real GDP Growth Rate and an inflation rate based on
PCEPI, which is a measure of the average price of consumption goods in the U.S.We can create a Data Frame and assign the columns/variables using a for loop. This is especially useful if you have data from different sources (i.e., FRED and some other sources).
# Libraries
from fredapi import Fred
import pandas as pd
# Setup acccess to FRED
fred_api_key = pd.read_csv('fred_api_key.txt', header=None)
fred = Fred(api_key=fred_api_key.iloc[0,0])
# Series to get
series = ['GDPC1','PCEPI']
# Get and append data to list
dl = []
for _, string in enumerate(series):
var = fred.get_series(string).to_frame(name=string)
dl.append(var)
print(var.head(2)); print(var.tail(2))
GDPC1
1947-01-01 2182.681
1947-04-01 2176.892
GDPC1
2025-01-01 23548.210
2025-04-01 23770.976
PCEPI
1959-01-01 15.164
1959-02-01 15.179
PCEPI
2025-07-01 126.949
2025-08-01 127.285
for _, string in enumerate(series):is a for loop that assigns a string,string, to each element ofseries.dlis a list with the data, notice the variables do not share the same datetime index, one is quarterly and the other is monthly, i.e., the data has mixed frequency. Furthermore, the first and last date of each variable is different.
# Concatenate data to create data frame (time-series table)
df = pd.concat(dl, axis=1).sort_index()
df.columns = ['RGDP','PCEPI']
# Display data
print(f'len(df) = {len(df)}')
print(df.head(4))
print(df.tail(4))
len(df) = 848
RGDP PCEPI
1947-01-01 2182.681 NaN
1947-04-01 2176.892 NaN
1947-07-01 2172.432 NaN
1947-10-01 2206.452 NaN
RGDP PCEPI
2025-05-01 NaN 126.380
2025-06-01 NaN 126.743
2025-07-01 NaN 126.949
2025-08-01 NaN 127.285
pd.concatcreates a data frame (time-series table),df, with a common datetime index but with mixed-frequency data, i.e.,RGDPhas values every quarter andPCEPIhas values every month and any missing values are filled in withNaN(i.e., Not a Number)
# Resample/reindex to quarterly frequency
df = df.resample('QE').last()
# Display data
print(f'len(df) = {len(df)}')
print(df.head(2))
print(df.tail(2))
len(df) = 315
RGDP PCEPI
1947-03-31 2182.681 NaN
1947-06-30 2176.892 NaN
RGDP PCEPI
2025-06-30 23770.976 126.743
2025-09-30 NaN 127.285
dfhad mix-frequency data. The pandas methodsresampleresamples the data frame to a desired common frequency, which is usually the lowest frequency of all the variables. That is a quarterly frequency here.resample('QE-DEC').last()resamples all variables to a quarterly frequency using the last value in each quarterly interval, and it reindexes the entire DataFrame such that each value corrresponds to the last day of the quarter (and is now standard practice inpandas, in contrast to FRED where each quarterly value was assigned to the first day).dfnow contains fewer rows, one for each quarter. The variablePCEPIis stillNaNat the beginning of the sample, andRGDPis missing a value for the end of the sample.
# Import libraries
import numpy as np
# Real GDP Growth Rate (percent change)
df['logRGDP'] = np.log(df.RGDP)
df['growth_rate'] = 100*(df.logRGDP - df.logRGDP.shift(4))
# PCE inflation rate (percent change)
df['logPCEPI'] = np.log(df.PCEPI)
df['inf_rate'] = 100*(df.logPCEPI - df.logPCEPI.shift(4))
# Display data
pd.options.display.float_format = '{:,.2f}'.format
print(df.tail(4))
# Latest Real GDP value
print()
print(f'2024Q3 real GDP Year over Year Growth Rate = \
{df.growth_rate['2024-09-30']:.2f}%')
RGDP PCEPI logRGDP growth_rate logPCEPI inf_rate
2024-12-31 23,586.54 124.98 10.07 2.37 4.83 2.69
2025-03-31 23,548.21 125.94 10.07 2.00 4.84 2.33
2025-06-30 23,770.98 126.74 10.08 2.06 4.84 2.56
2025-09-30 NaN 127.28 NaN NaN 4.85 2.48
2024Q3 real GDP Year over Year Growth Rate = 2.75%
# Import libraries
import matplotlib.pyplot as plt
# Plot options
# Sub sample
date_start = '01-01-1960'
date_end = '12-31-2023'
# Variables to plot
# Variable Plot title
plotme = [
['growth_rate', 'Real GDP Year over Year Growth Rate'],
['inf_rate', 'PCE Year over Year Inflation Rate']]
# Plot variables
fig, axs = plt.subplots(len(plotme),figsize=(6.5,4))
for idx, ax in enumerate(axs.flat):
ax.plot(df[plotme[idx][0]][date_start:date_end])
ax.set_title(plotme[idx][1])
ax.yaxis.set_major_formatter('{x:.0f}%')
ax.grid(); ax.autoscale(tight=True); ax.label_outer()
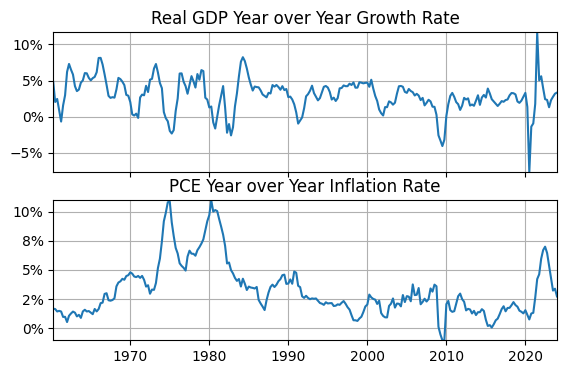
plt.subplots(len(vars))creates a figure with 2 subplotsfor idx, ax in enumerate(axs.flat):is a for loop that assigns an integer index,idx, and axis handle,ax, to each element ofaxs.flatthat indicate the subplot being formatted and where the data is plotted.ax.label_outer()skips the year label on the first plot and only shows it on the second axis.
Conclusion#
We used a for loop to assign multiple time series to a pandas DataFrame. Then we resampled the variables in the DataFrame to a common lower frequency. Based on those values, we calculated year-over-year real GDP growth and PCE inflation rates. Finally, we used a loop to plot both rates in a single figure.