Jupyter Notebook¶
by Professor Throckmorton
for Time Series Econometrics
W&M ECON 408/PUBP 616
Slides
This cell contains Markdown with the title (i.e., a section title preceded by #) and other important information.
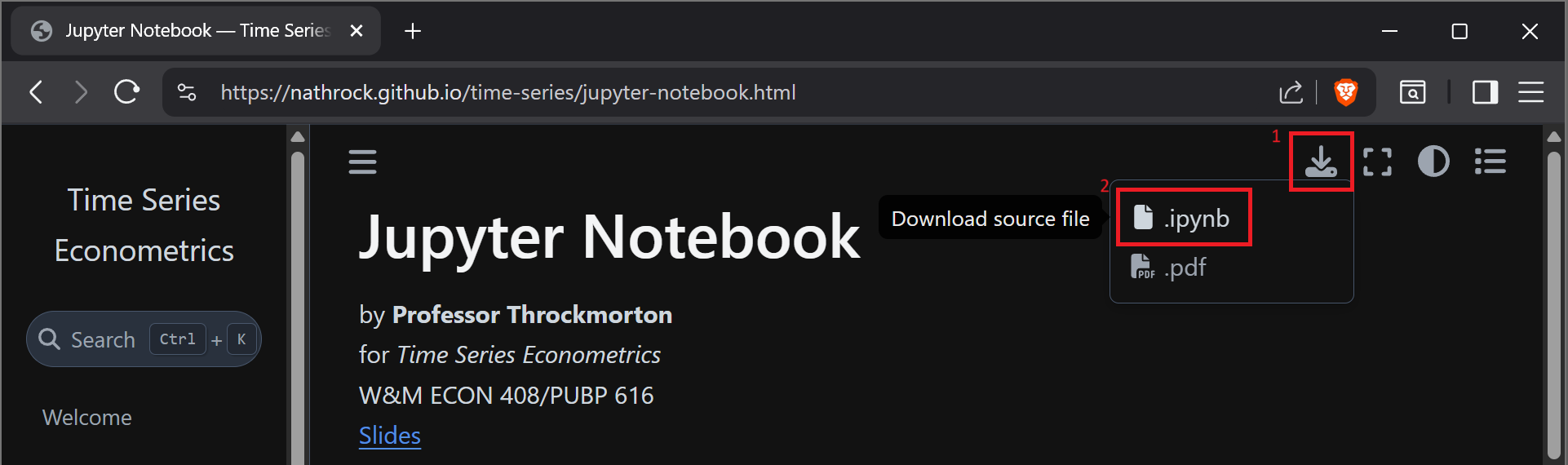
You may download every notebook in this course by clicking on the download button in the upper right and selecting ".ipynb".
Summary¶
This Jupyter Notebook contains cells with examples of Markdown, $\LaTeX$, and Python. These are versatile tools and the output is easy to create, read, and share.
Markdown¶
Markdown is a simple and easy-to-use markup language you can use to format virtually any document. For Markdown basic syntax, please see https://www.markdownguide.org/basic-syntax/.
If you open this notebook on https://jupyterhub.wm.edu (or JupyterLab locally), there is a dropdown menu in the toolbar above to select whether a cell contains Markdown or Code.
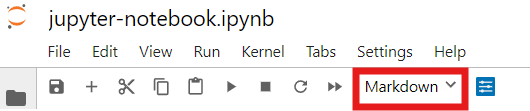
Note: I embeded this screenshot by simply copying and pasting the image into this Markdown cell. You may also save images in a/the sub/directory where the notebook is located and embed them, e.g., .
$\LaTeX$¶
You can typeset $\LaTeX$ in a Markdown cell (and also when labeling plots in Python). Here is a $\LaTeX$ math cheat sheet.
$\LaTeX$ surrounded by a single dollar sign, $...$, is typeset inline, e.g., $y = x^2$ becomes $y = x^2$. However, $\LaTeX$ surrounded by double dollar signs, $$...$$, is typeset on a separate line. For example, the Gaussian function, or the normal distribution's probability density function (PDF), is
$$ f(x) = \frac{1}{\sqrt{2\pi\sigma^2}}\exp\left\{\frac{(x-\mu)^2}{2\sigma^2}\right\}. $$
is the result of
$$
f(x) = \frac{1}{\sqrt{2\pi\sigma^2}}\exp\left\{\frac{(x-\mu)^2}{2\sigma^2}\right\}.
$$
If you want to list a system of $N$ equations, then I recommend this syntax:
\begin{gather*}
u(c,\ell) = \log(c) + \chi \log(\ell), \\
\ell = 1 - n, \\
c + i + g = f(k,n), \\
f(k,n) = k^\alpha n^{1-\alpha}.
\end{gather*}
which looks like
\begin{gather*} u(c,\ell) = \log(c) + \chi \log(\ell), \\ \ell = 1 - n, \\ c + i + g = f(k,n), \\ f(k,n) = k^\alpha n^{1-\alpha}. \end{gather*}
# Import libraries
# Plotting
import matplotlib.pyplot as plt
# Scientific computing
import numpy as np
# Set rng seed
rng = np.random.default_rng(seed=0)
Variables¶
The following code cell assigns the sample size to T and randomly generated data from a standard normal distribution to eps, i.e., $\varepsilon_t \overset{i.i.d.}{\sim} N(0,1)$ ($\varepsilon_t$ is a random variable with a standard normal distribution that is independently and identically distributed across time). eps is also known as white noise data.
# Sample size
T = 201
# White noise data
eps = rng.standard_normal(T)
Histogram¶
The following cell will create a histogram of eps. If we weren't thinking about eps as a time series variable, then the histogram could represent the distribution of the variable in the cross section dimension.
# Plot histogram
plt.figure(figsize=(6.5,3))
plt.hist(eps,edgecolor='black',density='true')
plt.xlabel('White-noise data')
plt.ylabel('probability')
plt.grid()

Time series¶
But since we want to think of eps as a time series variable, we should plot it as a function of time.
# Plot time series
plt.figure(figsize=(6.5,3))
plt.plot(eps)
plt.title('White-noise data')
plt.xlabel('Time')
plt.xlim([0,T-1])
plt.grid()

Slides¶
Slides are easily created from a Jupyter Notebook (via reveal.js). For example, see Jupyter Notebook Slides.
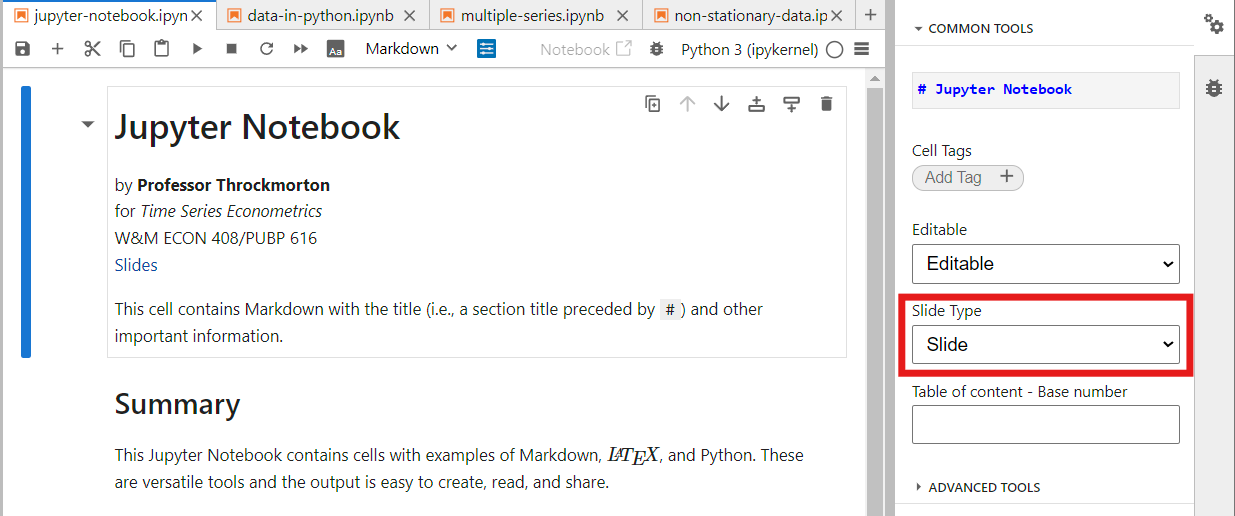
- Open the property inspector by clicking the double gears in the upper-right-hand corner, and assign the "Slide Type" field.
- "Slide" starts a new slide
- "Fragment" does not create a new slide and instead hides the content until the presenter increments forward
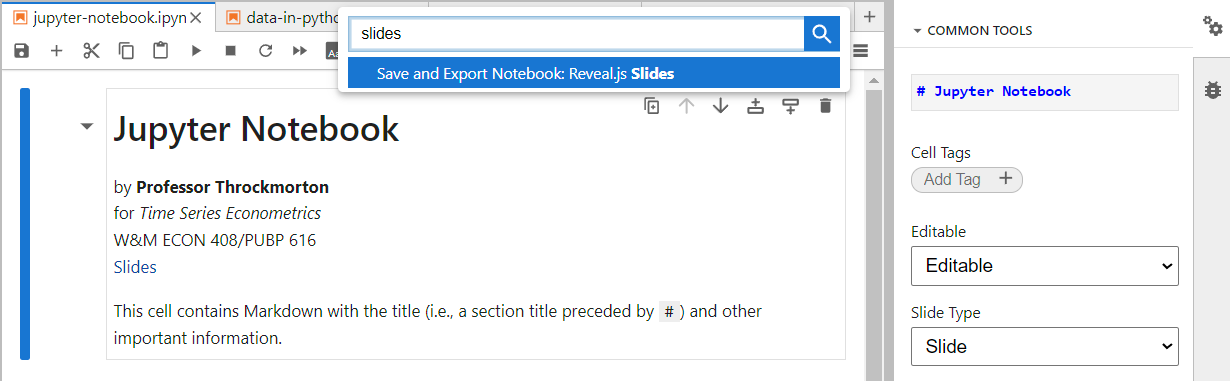
- Press ctrl/command+shift+c (to open the command palette) and type "slides". Press enter or click "Save and Export Notebook: Reveal.js Slides".
- Save the html file, which you can then open in any browser.
Conclusion¶
- Jupyter Notebooks are versatile tools to display, run, and view the output of programs in Python (or other languages), to typeset math expressions in $\LaTeX$, and to format text and analysis in Markdown.
- Furthermore, Jupyter Notebooks are easily converted to presentation slides with the built-in support for
reveal.js.